1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
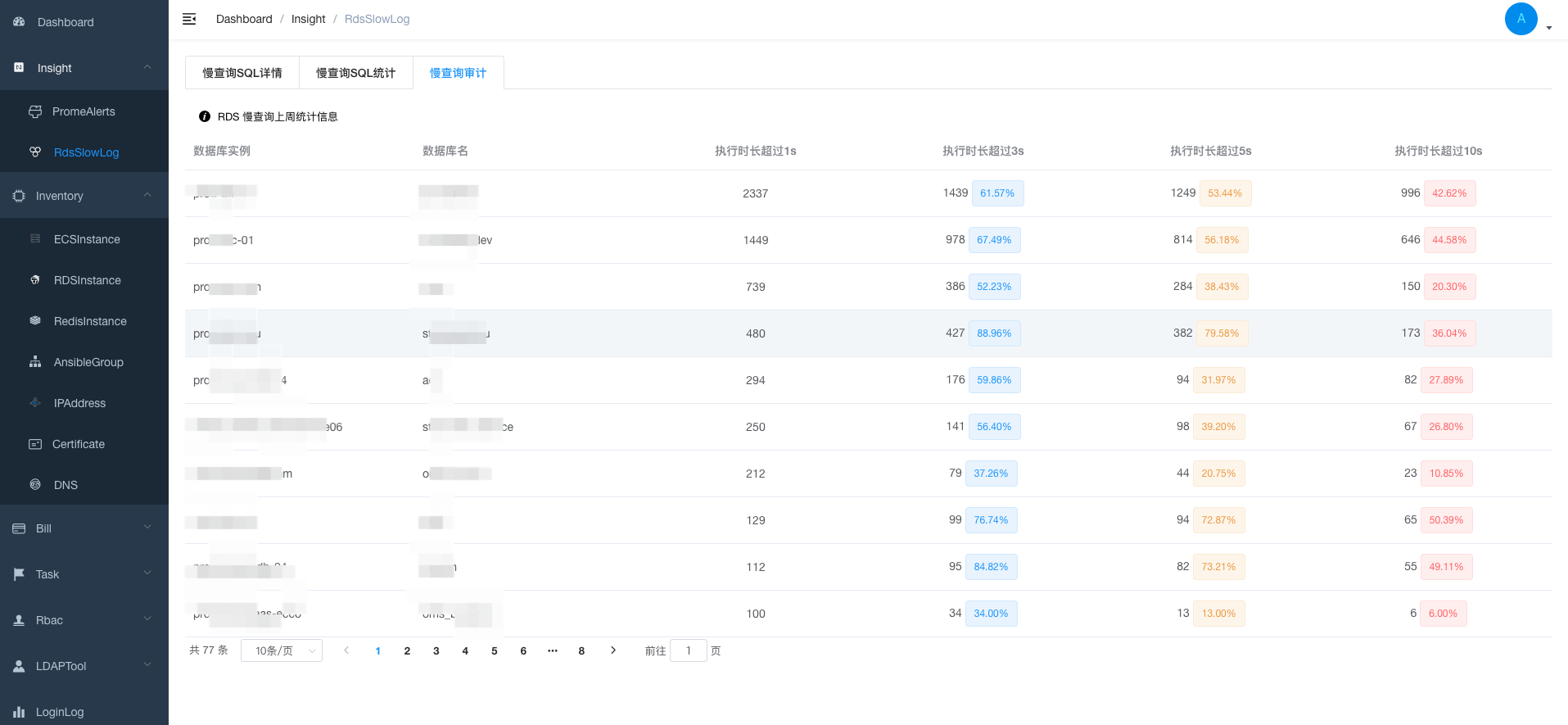
| def audit_rds_slowlog(module, startDate, endDate):
"""分析一段时间内的rds slowlog"""
result_1 = (module.objects
.filter(create_time__gte=startDate, create_time__lte=endDate, max_execution_time__gte=1)
.values('db_name','rds_name')
.annotate(dcount_1=Count('db_name'))
.order_by()
)
result_3 = (module.objects
.filter(create_time__gte=startDate, create_time__lte=endDate, max_execution_time__gte=3)
.values('db_name','rds_name')
.annotate(dcount_3=Count('db_name'))
.order_by()
)
result_5 = (module.objects
.filter(create_time__gte=startDate, create_time__lte=endDate, max_execution_time__gte=5)
.values('db_name','rds_name')
.annotate(dcount_5=Count('db_name'))
.order_by()
)
result_10 = (module.objects
.filter(create_time__gte=startDate, create_time__lte=endDate, max_execution_time__gte=10)
.values('db_name','rds_name')
.annotate(dcount_10=Count('db_name'))
.order_by()
)
for item_1 in result_1:
for item_3 in result_3:
if item_1["db_name"] == item_3["db_name"] and item_1["rds_name"] == item_3["rds_name"]:
item_1["dcount_3"] = item_3["dcount_3"]
for item_1 in result_1:
for item_5 in result_5:
if item_1["db_name"] == item_5["db_name"] and item_1["rds_name"] == item_5["rds_name"]:
item_1["dcount_5"] = item_5["dcount_5"]
for item_1 in result_1:
for item_10 in result_10:
if item_1["db_name"] == item_10["db_name"] and item_1["rds_name"] == item_10["rds_name"]:
item_1["dcount_10"] = item_10["dcount_10"]
result = sorted(result_1, key=itemgetter('dcount_1'), reverse=True)
return result
class RDSSlowlogViewSet(LogMixin, DefaultRBACMixin, viewsets.ReadOnlyModelViewSet):
resource_name = 'rds_slowlog'
serializer_class = serializers.ListRDSSlowlogSerializer
filterset_fields = ['db_name', 'rds_name','sql_hash','create_time']
search_fields = ['rds_name']
def get_queryset(self):
start_date = self.request.query_params.get('start_date', None)
end_date = self.request.query_params.get('end_date', None)
max_execution_time = self.request.query_params.get('max_execution_time__gte', None)
qs = RDSSlowLog.objects.all()
if start_date and end_date:
qs = qs.filter(create_time__gte=start_date,create_time__lte=end_date)
if max_execution_time:
qs = qs.filter(max_execution_time__gte=max_execution_time)
return qs
@action(methods=['get'], detail=False)
def audit(self, request, *args, **kwargs):
start_date, end_date = getlastWeektime()
start_date = start_date.strftime('%Y-%m-%d')
end_date = end_date.strftime('%Y-%m-%d')
redis_conn = get_redis_connection('default')
if redis_conn.exists(f"audit:rds_slowlog:{start_date}-{end_date}"):
result = redis_conn.get(f"audit:rds_slowlog:{start_date}-{end_date}")
return Response(data=json.loads(result), status=status.HTTP_200_OK)
result = audit_rds_slowlog(RDSSlowLog, start_date, end_date)
redis_conn.set(f"audit:rds_slowlog:{start_date}-{end_date}", json.dumps(result))
redis_conn.persist(f"audit:rds_slowlog")
return Response(data=result, status=status.HTTP_200_OK)
@action(methods=['get'], detail=False)
def csv_download(self, request):
"""不想写文件在容器本地内 数据量庞大 采用导出csv的方法"""
def iter_objects():
objects = self.get_queryset()
yield "RDS, 数据库名, 开始执行时间, 执行时长, 锁定时长, 解析行数, SQL语句\n"
for i, ins in enumerate(objects):
rds_name = ins.rds_name
db_name = ins.db_name
execution_start_time = (ins.execution_start_time + timedelta(hours=8)).strftime("%Y-%m-%d %H:%M:%S")
lock_times = ins.lock_times
parse_row_count = ins.parse_row_count
sql_text = ins.sql_text.replace("\n", "").replace("\r","").replace(",", ",")
query_time_ms = ins.query_time_ms
yield f"{rds_name}, {db_name}, {execution_start_time}, {query_time_ms}, {lock_times}, {parse_row_count}, {sql_text}\n"
response = StreamingHttpResponse(content_type='text/csv; charset=utf-8')
response['Content-Disposition'] = "attachment;filename=slowLogRecord.csv"
response['Content-Type'] = "application/octet-stream"
response['Cache-Control'] = 'no-cache'
response.streaming_content = iter_objects()
return response
|